Over the break, I was looking at competitive coding and had a proper look at different types of algorithms. I was presented with a task to find the shortest path to traverse a graph – a classical algorithmic problem that is surprisingly common in both Computational Chemistry and Biology. In this blog post, I am attempting to explain to my future self how to do these searches using efficient algorithms.

Depth-First Search (DFS)
DFS(G,u)
u.visited = true
for each v in G.NeighbourOf(u)
if v.visited == false
DFS(G,v)
init()
for each u in G
u.visited = false
for each u in G
DFS(G,u)
and the C++ snippets (from this link): void init() {
visited = new bool[numVertices];
for(int i = 0; i < numVertices; i++) {
visited[i] = false;
}
}
void DFS(int vertex) {
visited[vertex] = true;
list neighbourList = neighbourLists[vertex];
list::iterator i;
for(i = adjList.begin(); i != adjList.end(); ++i)
if(!visited[*i])
DFS(*i);
} 
Explanation of Figure 2:
Starting with node A, add all neighbours to the stack. From the end of the stack (the last node), search for all of its neighbours. Repeat until all nodes have been visited and the stack becomes empty.
Thus, we start with A, add B, C and D to the stack. Since D is the last of the stack, we look for its neighbours, in this case, F. Taking away D and F, we have C, which is connected to both E and F. Since F has been visited, it only returns E. Finally, we add the remaining B to the output.
Breadth-First Search (BFS)
BFS(G,u)
create an empty queue q
u.visited = true
q.enqueue(u)
while queue is not empty
v = q[0] // head of queue
q.dequeue()
for each x in G.NeighbourOf(v)
if v.visited == false
q.enqueue(v)
v.visited = true
init()
for each u in G
u.visited = false
for each u in G
BFS(G,u)
and the C++ snippets (from this link): void BFS(int startVertex) {
visited = new bool[numVertices];
for(int i = 0; i < numVertices; i++) visited[i] = false;
list queue;
visited[startVertex] = true;
queue.push_back(startVertex);
list::iterator i;
while(!queue.empty()) {
int currVertex = queue.front();
queue.pop_front();
for(i = neighbourLists[currVertex].begin(); i != neighbourLists[currVertex].end(); ++i)
{
int neighbourVertex = *i;
if(!visited[neighbourVertex])
{
visited[adjVertex] = true;
queue.push_back(adjVertex);
}
}
}
} 
Explanation of Figure C:
Starting with node A, we add all of its neighbours to the queue. We then start appending neighbours of the node at the start of the queue, to the end of the queue.
Thus, we start with A, add B, C and D. Since B does not have any neighbours, it is popped and added to the output. C has neighbours E and F, so they start queuing at the back after D. Finally D has no unvisited neighbours, and the queue exits according to the order it was added.
Range Minimum Query (RMQ)
RMQ answers the question:
Given an array, where (the index/position) can I find the the minimum value between two given indices?

In Python, it is simply numpy.argmin.
In lower-level languages, you could have a naive algorithms:
#define MAXN 10001
/**
* Naive RMQ
*
* @param M[MAXN][MAXN] matrix of the positions of the elements with the minimum values given range (row,column)
* @param A[MAXN] input array of values
* @param N size of A
*/
void rmq1(int M[MAXN][MAXN], int A[MAXN], int N) {
int i,j;
for (i=0; i<N; i++) {
M[i][i] = i;
}
for (i=0; i<N; i++){
for (j=i+1; j<N; j++) {
if (A[M[i][j-1]]<A[j]) M[i][j] = M[i][j-1];
else M[i][j] = j;
}
}
} There are two ways to preprocess the matrix and speed up the query, using sparse table or segment tree.
Sparse table splits the array into sub-arrays of length 
![M[i][j] = M[i][j-1]](https://s0.wp.com/latex.php?latex=+M%5Bi%5D%5Bj%5D+%3D+M%5Bi%5D%5Bj-1%5D+&bg=ffffff&fg=000&s=0&c=20201002)
![A[M[i][j-1]] \leq A[M[i+2^{j-1}-1][j-1]]](https://s0.wp.com/latex.php?latex=+A%5BM%5Bi%5D%5Bj-1%5D%5D+%5Cleq+A%5BM%5Bi%2B2%5E%7Bj-1%7D-1%5D%5Bj-1%5D%5D+&bg=ffffff&fg=000&s=0&c=20201002)
![M[i][j] = M[i+2^{j-1}-1][j-1]](https://s0.wp.com/latex.php?latex=M%5Bi%5D%5Bj%5D+%3D+M%5Bi%2B2%5E%7Bj-1%7D-1%5D%5Bj-1%5D&bg=ffffff&fg=000&s=0&c=20201002)
/**
* Initialize sparse table
*
* @param M[MAXN][LOGMAXN] Output matrix
* @param A[MAXN] Input array
* @param N Length of array A
*/
void st(int M[MAXN][LOGMAXN], int A[MAXN], int N)
{
int i, j;
// Initialize the boundary of the matrix
for (i = 0; i < N; i++) M[i][0] = i;
// Fill in the matrix
for (j = 1; 1 << j <= N; j++)
for (i = 0; i + (1 << j) - 1 < N; i++)
if (A[M[i][j - 1]] < A[M[i + (1 << (j - 1))][j - 1]])
M[i][j] = M[i][j - 1];
else
M[i][j] = M[i + (1 << (j - 1))][j - 1];
} To query this table, we let 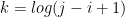
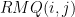
![RMQ(i,j) = M[i][k]](https://s0.wp.com/latex.php?latex=RMQ%28i%2Cj%29+%3D+M%5Bi%5D%5Bk%5D&bg=ffffff&fg=000&s=0&c=20201002)
![A[M[i][k]] \leq A[M[j-2^{k}+1][k]]](https://s0.wp.com/latex.php?latex=A%5BM%5Bi%5D%5Bk%5D%5D+%5Cleq+A%5BM%5Bj-2%5E%7Bk%7D%2B1%5D%5Bk%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![RMQ(i,j)=M[j-2^{k}+1][k]](https://s0.wp.com/latex.php?latex=RMQ%28i%2Cj%29%3DM%5Bj-2%5E%7Bk%7D%2B1%5D%5Bk%5D&bg=ffffff&fg=000&s=0&c=20201002)
Alternatively you can go through a segment tree (Figure 4), subdividing the array into 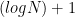
/**
* Initialize the matrix *
* @param node index of node to be populated (=1)
* @param b beginning index of the array (=0)
* @param e end index of the array (=array length N-1)
* @param M[MAXIND] matrix for the values in the subtress
* @param A[MAXN] array with values
* @param N length of array A
*/
void initialize(int node, int b, int e, int M[MAXIND], int A[MAXN], int N) {
if (b==e) M[node] = b;
else { // compute the values in the left and right subtrees
initialize(2*node, b, (b+e)/2, M, A, N);
initialize(2*node + 1, (b+e)/2 + 1, e, M, A, N);
// search for minimum value in first and second
// half of interval
if (A[M[2*node]] <= A[M[2*node+1]]) M[node] = M[2*node];
else M[node] = M[2*node+1];
}
} and the query function is:
/**
* Query the RMQ matrix generated by the segment tree *
* @param node index of node to be populated (=1)
* @param b beginning index of the array (=0)
* @param e end index of the array (=array length-1)
* @param M[MAXIND] matrix for the values in the subtress
* @param A[MAXN] array with values
* @param i beginning index of the query
* @param j end index of the query
*/
int query(int node, int b, int e, int M[MAXIND], int A[MAXN], int i, int j) {
int p1, p2;
// If the current interval does not intersect
// with the query interval
if (i>e || j<b) return -1;
// If the current interval is included in the
// query interval
if (b>=i && e<=j) return M[node];
// Find the min position in the left and right part of the interval
p1 = query(2*node, b, (b+e)/2, M, A, i, j);
p2 = query(2*node+1, (b+e)/2+1, e, M, A, i, j);
// Return the position with the minimum value
if (p1 == -1) return p2;
if (p2 == -1) return p1;
if (A[p1]<=A[p2]) return p1;
else return p2;
} Lowest Common Ancestor (LCA)
LCA wants to look for the furthest node from the root, that sprouts the query nodes, i.e. the ancestor node from which the branches split.

One way is to precompute with recursion:
/*
* Preprocess the tree for the LCA
*
* @param N Length of P
* @param T[MAXN] List of father nodes to each element
* @param P[MAXN][LOGMAXN] Output list of parent nodes
*/
void init(int N, int T[MAXN], int P[MAXN][LOGMAXN])
{
int i, j;
// Initialize the elements in P with -1
for (i = 0; i < N; i++)
P[i][0] = T[i]; // The first ancestor of every node i is T[i], the father node
for (j = 1; (1 << j) < N; j++)
P[i][j] = -1;
// Fill the matrix
for (j = 1; 1 << j < N; j++)
for (i = 0; i < N; i++)
if (P[i][j - 1] != -1) P[i][j] = P[P[i][j - 1]][j - 1];
} and the query code:
/**
* Query the LCA
*
* @param N Length of P
* @param P[MAXN][LOGMAXN] List of parent nodes
* @param T[MAXN] List of father nodes to each element
* @param L[MAXN] Level of the nodes
* @param p Query node 1
* @param q Query node 2
*/
int query(int N, int P[MAXN][LOGMAXN], int T[MAXN],
int L[MAXN], int p, int q)
{
int log, i;
// If p is on a higher level than q, swap the two.
if (L[p] < L[q]) swap(p,q);
// Find log(L[p])
for (log = 1; 1 << log <= L[p]; log++);
log–;
// Find the ancestor of p that has the
// same level as that of q
// This is going up the level by traversing in
// reversed order
for (i = log; i >= 0; i–-)
if (L[p] - (1 << i) >= L[q])
p = P[p][i];
// If they coincide, p is a direct ancestor of q
if (p == q)
return p;
// Finally, LCA(p, q)
for (i = log; i >= 0; i–-)
if (P[p][i] != -1 && P[p][i] != P[q][i])
p = P[p][i], q = P[q][i];
return T[p];
} Bonus: Reducing LCA to RMQ
It may be possible to phrase the LCA question in terms of RMQ and use the RMQ algorithms to solve it (Figure 5).
First you will construct three arrays:
- E [1,2*N-1] Euler tour
- L [1,2*N-1] Levels of the nodes visited during E
- H [1,N] Index of the first occurrence of the node i in E
Figure shows the three arrays. Taking H[u] < H[v] (swap u and v if not), we need to find the ancestoral node (i.e. node with the smallest level) in the Euler tour E[H[u]…H[v]]. This corresponds to the “level” stored in array L, thus the RMQ of L[H[u],H[v]]. To find the name of the node at this point, we access E[RMQ(L[H[u],H[v]])].
Taking an example of LCA(5,8):
- u=5, v=8
- H[5] = 8, H[v] = 13
- RMQ(L[8,13]) = 9
- E[9] = 2