A crash course in Medicinal Chemistry

where E = enzyme, S = substrate, P = product.
Michaelis-Menten equation:
![V = \frac{V_{max}[S]}{K_m+[S]}](https://s0.wp.com/latex.php?latex=+V+%3D+%5Cfrac%7BV_%7Bmax%7D%5BS%5D%7D%7BK_m%2B%5BS%5D%7D+&bg=ffffff&fg=000&s=0&c=20201002)

Turning it into an equation with a slope:
![\frac{1}{V} = \frac{K_m+[S]}{V_{max}[S]} = \frac{K_m}{V_{max}} \frac{1}{[S]} + \frac{1}{V_{max}}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7BV%7D+%3D+%5Cfrac%7BK_m%2B%5BS%5D%7D%7BV_%7Bmax%7D%5BS%5D%7D+%3D+%5Cfrac%7BK_m%7D%7BV_%7Bmax%7D%7D+%5Cfrac%7B1%7D%7B%5BS%5D%7D+%2B+%5Cfrac%7B1%7D%7BV_%7Bmax%7D%7D&bg=ffffff&fg=000&s=0&c=20201002)
which renders the Lineweaver–Burk plot:
Assume:

The equilibrium between forward and backward reaction is:
![K_D = \frac{[A]^a[B]^b}{[AB]^x}](https://s0.wp.com/latex.php?latex=K_D+%3D+%5Cfrac%7B%5BA%5D%5Ea%5BB%5D%5Eb%7D%7B%5BAB%5D%5Ex%7D&bg=ffffff&fg=000&s=0&c=20201002)
Clark’s occupancy theory suggests:
![\frac{E}{E_{max}} = \frac{[L]}{[L]+K_D}](https://s0.wp.com/latex.php?latex=%5Cfrac%7BE%7D%7BE_%7Bmax%7D%7D+%3D+%5Cfrac%7B%5BL%5D%7D%7B%5BL%5D%2BK_D%7D&bg=ffffff&fg=000&s=0&c=20201002)


Drug A: Efficacious but not potent;
Drug B: Potent but not efficacious
Rearranging the Scatchard equation, which describes the ratio of bound ligands to the total number of available binding sites, we get this equation for the Scatchard plot: ![\frac{[PL]}{[L]} = -\frac{1}{K_D}[PL]+\frac{[PL]_{max}}{K_D}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5BPL%5D%7D%7B%5BL%5D%7D+%3D+-%5Cfrac%7B1%7D%7BK_D%7D%5BPL%5D%2B%5Cfrac%7B%5BPL%5D_%7Bmax%7D%7D%7BK_D%7D&bg=ffffff&fg=000&s=0&c=20201002)
![K_D = \frac{[PL]}{[P][L]}](https://s0.wp.com/latex.php?latex=K_D+%3D+%5Cfrac%7B%5BPL%5D%7D%7B%5BP%5D%5BL%5D%7D&bg=ffffff&fg=000&s=0&c=20201002)

Cheng-Prusoff Equation:
![K_i = \frac{IC_{50}}{1+\frac{[S]}{K_D}}](https://s0.wp.com/latex.php?latex=K_i+%3D+%5Cfrac%7BIC_%7B50%7D%7D%7B1%2B%5Cfrac%7B%5BS%5D%7D%7BK_D%7D%7D&bg=ffffff&fg=000&s=0&c=20201002)

Lipinski’s rule of five (RO5)
- Molecular Mass
500 Da
- Lipophilicity (logP)
- Number of Hydrogen Bond Acceptors
- Number of Hydrogen Bond Donors
Rule of three (RO3)
- Molecular Mass
- log P
- Number of Hydrogen Bond Acceptors
- Number of Hydrogen Bond Donors
- Number of rotatable bonds
Lipophilicity is primarily associated with solubility, absorption, membrane penetration and distribution, i.e. the ADME and PKPD properties of the drug. This is usually taken as a ratio between octan-1-ol and water: 
Lipophilic efficiency:

Quality drug candidates usually have high LiPE 
Michaelis constant – a kinetic constant that represents the relationship between substrate concentration and reaction speed.
Affinity
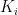

Stronger binder = lower
Potency
The concentration of competing ligand which displaces 50% of the specific binding of the drug. This is a relevative value depending on the drug concentration.
More potent = lower

Efficacy
The ability to impact a biological pathway.
More efficacious = higher

Potency
The concentration of drug required to produce 50% of the possible effect.
More potent = lower

Partition coefficient
![log P_{octanol/water}=log(\frac{[Drug]^{un-ionized}_{octanol}}{[Drug]^{un-ionized}_{water}})](https://s0.wp.com/latex.php?latex=log+P_%7Boctanol%2Fwater%7D%3Dlog%28%5Cfrac%7B%5BDrug%5D%5E%7Bun-ionized%7D_%7Boctanol%7D%7D%7B%5BDrug%5D%5E%7Bun-ionized%7D_%7Bwater%7D%7D%29&bg=ffffff&fg=000&s=0&c=20201002)
Distribution coefficient (pH-dependent)
![log D_{octanol/water}=log(\frac{[Drug]^{ionized}_{octanol}+[Drug]^{un-ionized}_{octanol}}{[Drug]^{ionized}_{water}+[Drug]^{un-ionized}_{water}})](https://s0.wp.com/latex.php?latex=log+D_%7Boctanol%2Fwater%7D%3Dlog%28%5Cfrac%7B%5BDrug%5D%5E%7Bionized%7D_%7Boctanol%7D%2B%5BDrug%5D%5E%7Bun-ionized%7D_%7Boctanol%7D%7D%7B%5BDrug%5D%5E%7Bionized%7D_%7Bwater%7D%2B%5BDrug%5D%5E%7Bun-ionized%7D_%7Bwater%7D%7D%29&bg=ffffff&fg=000&s=0&c=20201002)
- Typically observed at pH 7.4
- 0-3: optimal range
- ~2 for CNS projects (most favourable for blood-brain-barrier permeation)
- <0: highly hydrophilic
- >5 highly lipophilic
Better if higher

Better if lower


